Why I Built RelayList.com
Like many folks, I've recently dived into Mastodon. I took the route of standing up my own server, and in the process noticed that it can feel a little lonely. Things like tags and the federated feed don't work all that well without a lively local population following others and posting often.
Relays help to create some of that activity by pushing the local feed from other servers to mine. Finding relays, though, is purely word of mouth at the moment. There are a handful of manually curated lists scattered across GitHub and the like, with many becoming out of date quickly as servers entropy or close registration. For this reason, I decided to build RelayList.com.
What is RelayList


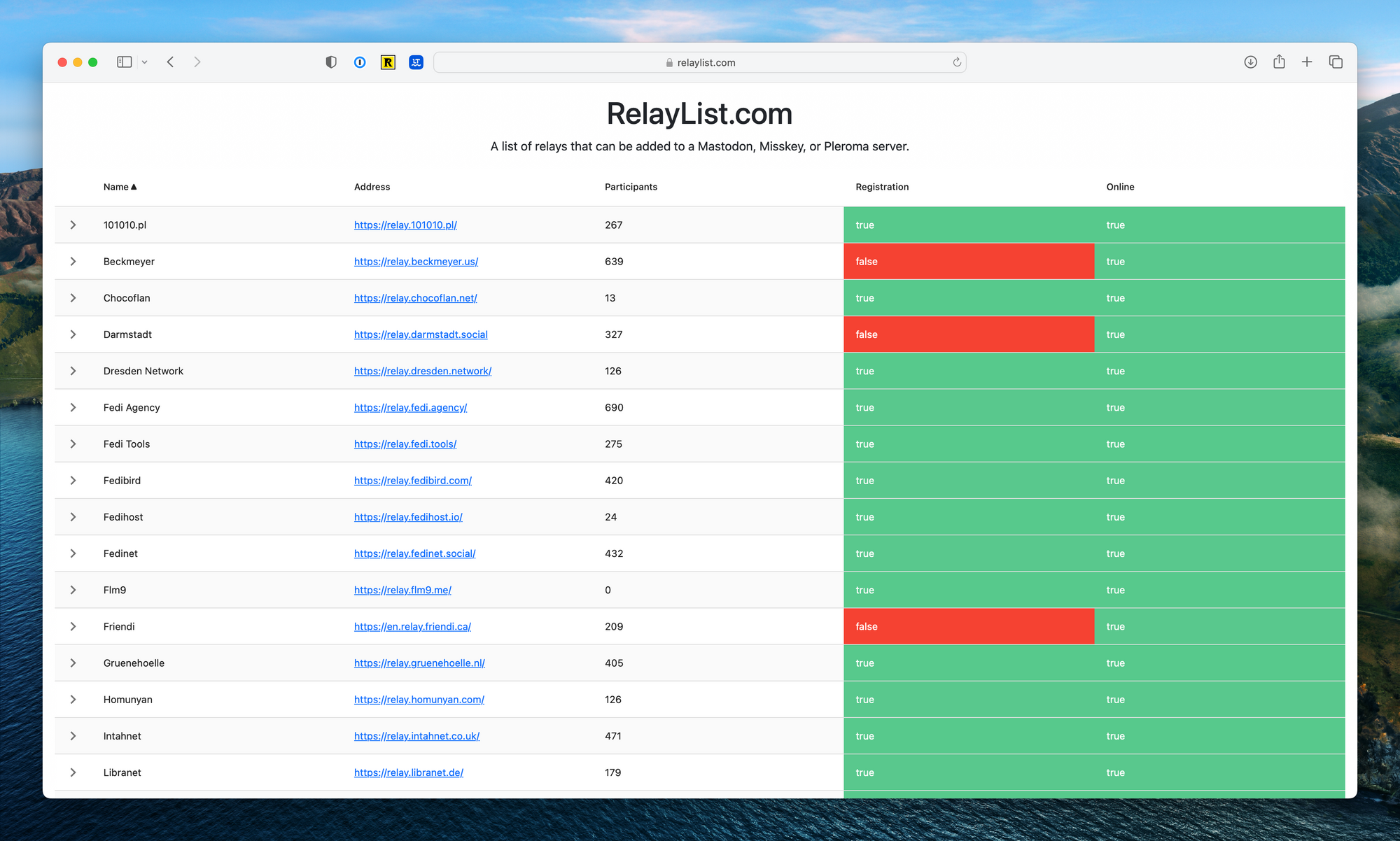
The site is fairly straightforward - it displays a list of relays, along with relevant information such as registration status, relay availability, the number of registered servers, and the links to add the relay to an instance. Keeping this information up-to-date manually would be challenging, so the service queries the relays every 30 minutes using published endpoints.
There is a basic API that populates this information (api.relaylist.com/relays) on the site. With this, anyone looking for a live relay can quickly see which are available and the number of servers subscribed, providing admins of smaller servers a faster path to federation.
I'd like to add a bit more to the site in the coming months. First up is listing the preferred language of the relay if known. Next, relays with a specific focus, such as sports or technology, will have that noted on the site. Finally, I'd like to provide a better idea of the volume admins can expect by adding the relay. This will require enumerating the active users of each server participating with the relay.
Architecture
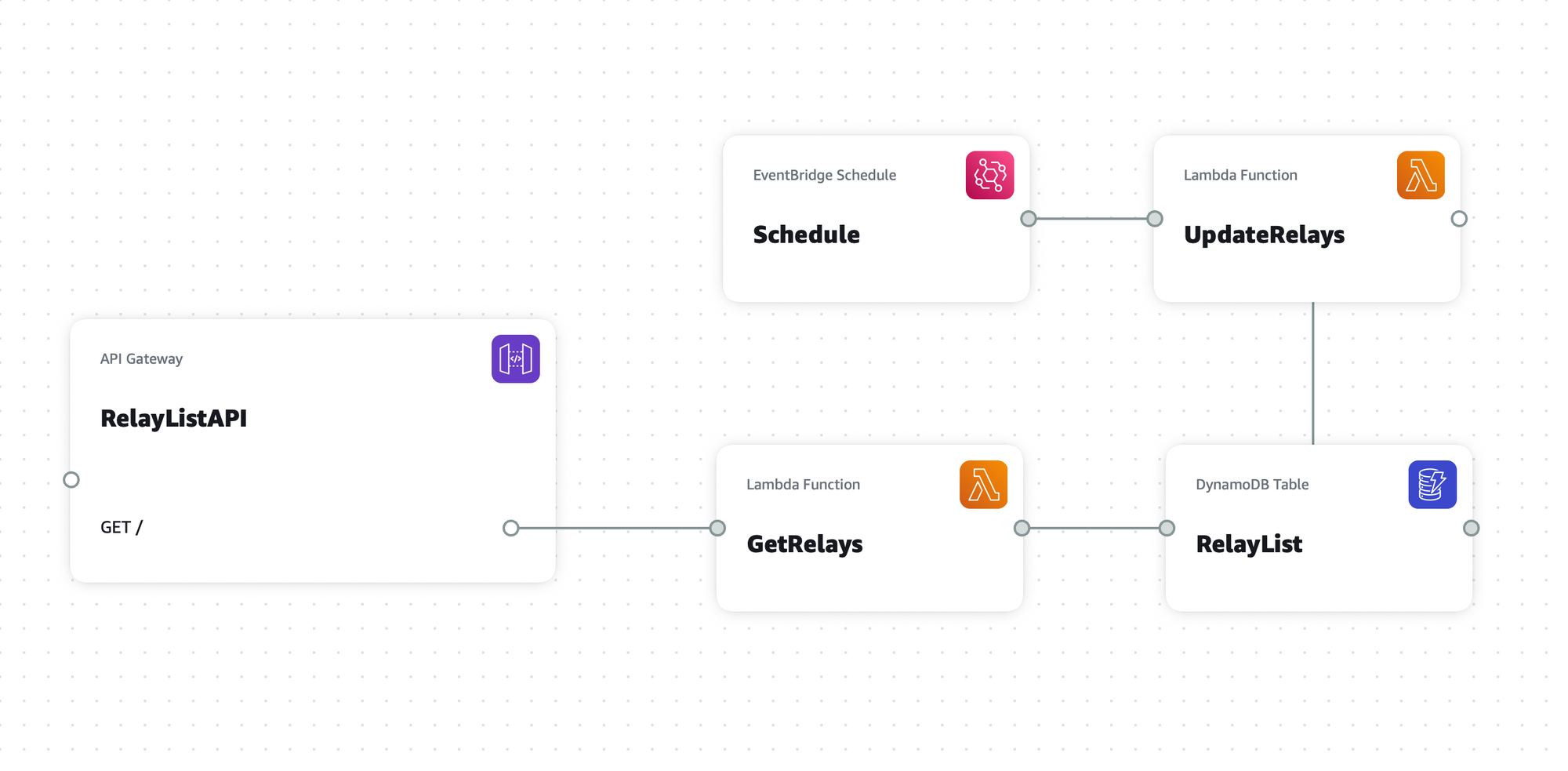
The site is running on AWS in a basic serverless architecture. I've used the AWS Serverless Application Model (SAM) to build and deploy the components. There are two primary components of the backend.
First, there is a Lambda function that runs every 30 minutes. Each time this function runs, it iterates over the list of relays stored in DynamoDB, looking up the nodeinfo URL by querying https://relayurl/.well-known/nodeinfo. This provides another URL that that contains a JSON document with the relevant information. The Lambda function queries this document, loading the information into the DynamoDB table.
I chose this pattern because some relays respond to this request slowly, requiring the content to be cached. In the future, if the list of relays grows much larger, I will need to re-architect this with AWS Step Functions to fan out these requests. This will also allow the site to update more often than the current 30-minute schedule.
The API runs on AWS API Gateway as a proxy for a Lambda function querying the DynamoDB table. All of this is also cached, reducing the load on the table. To prevent enormous bills and poor performance, I've configured throttling on this endpoint, though it doesn't require an API key at the moment.
 mlapida
mlapidaThe front end is a very basic Next.js application that dynamically loads the list of servers from the API. Admittedly, front end development is not my strongest skill, so this aspect of the site leaves a bit to be desired. The static web application is hosted on AWS through AWS Amplify.
Conclusion
My goal in creating RelayList is to help other small instance Mastodon administrators become more federated. Through more transparency, less word-of-mouth, and more automation, RelayList can help admins choose which relays to participate in. There's more to add to the site, and your feedback is always welcome. Please DM me if you'd like to add a relay or submit a feature request.


Comments ()